

Informatica Data Engineering Quality
Deliver fit-for-purpose big data with scalable, role-based data quality.
com.informatica.core.model.PersistentInlineNavigationElement@592a1de2
Overview
Manage all your big data on Spark or Hadoop in the cloud or in on-premises environments to ensure it is trusted and relevant.
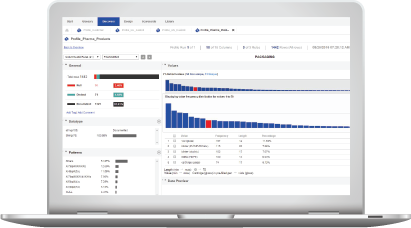
Reduce risk and increase productivity
Increase confidence in the external and internal sources of data that flow into your data lake. Use out-of-the-box templates to quickly discover and profile data to examine its structure and context.
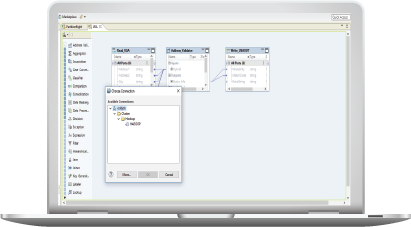
Accelerate big data and analytics initiatives
Generate insights faster with a no-code, visual development environment that increases developer productivity by up to 5x compared to hand coding.
com.informatica.core.model.PersistentInlineNavigationElement@67cfe1c
Key Features
Cleanse, standardize, and enrich all data—big and small—using an extensive set of prebuilt data quality rules including address verification.
Enrich and standardize any data at scale
Deploy pre-built data quality rules so you can easily handle the scale of big data to improve quality across the enterprise.
Enterprise discovery, search, and profiling
Understand the nature of your data and identify the relationships between various data objects.
Support data science projects’ success
Use relevant, accurate, clean, and valid data to operationalize your machine learning models.
Rich set of data quality transformations
Data standardization, validation, enrichment, de-duplication, and consolidation ensure delivery of high-quality information.
Role-based capabilities
Empowers business users and facilitates collaboration between IT and business stakeholders.
Intelligent data quality
Use AI-driven insights to automate the most critical tasks and streamline data discovery to increase productivity and effectiveness.

com.informatica.core.model.PersistentInlineNavigationElement@513e2a07
How can we help?



