How to Gain a Competitive Edge in Your Data Engineering Initiatives
Informatica advanced serverless capabilities help drive data engineering and data science projects at scale

Organizations rely on insights from analytics and AI to improve productivity and accelerate decision making. The challenge? Analytics and AI projects are data-hungry, and their success depends on a solid and cost-effective data engineering and integration foundation. Having the right data engineering and integration tools in place help enable organizations to access, integrate, transform, process and enrich data in a governed manner at scale in a cost-performant manner. It can also set you apart from the competition in today’s digital landscape.
To better understand their impact, let’s look at a real-world example of how data engineering and data integration can make a difference. Let’s say your data engineering and analytics team notices a spike in your compute workload and needs to ensure there is sufficient capacity. To do this, they pause their other work to send requests to the cloud vendor for more compute nodes.
The downside? That valuable time could have been better spent developing data pipelines and applications for your data integration projects. The bottom line — every hour spent provisioning machines, instantiating virtual machines (VMs), installing and patching updates is an hour lost in productivity. Not ideal in a demanding, high-pressure environment.
This is where Informatica Cloud Data Integration Advanced Serverless, a service of Intelligent Data Management Cloud (IDMC), comes in. Informatica Cloud Data Integration Advanced Serverless provides a zero footprint serverless deployment option, which eliminates the need to manage servers or infrastructure.
But before diving into advanced serverless, let me explain the difference between Informatica Cloud Data Integration (CDI) and Informatica Cloud Data Integration Elastic (CDI-E) to help you select the right solution for your use case.
How They Differ: Informatica Cloud Data Integration and Informatica Cloud Data Integration Elastic
Informatica CDI is a codeless data integration service available in IDMC. It enables data engineers to integrate data from different data sources. To start building data pipelines using Informatica CDI, you need to provision the infrastructure by selecting the compute.
Informatica CDI-E provides the same graphical user interface (GUI) like Informatica CDI. The main difference between Informatica CDI and Informatica CDI-E is the Kubernetes cluster and Spark runtime that can automatically scale the compute up and down based on the data workload. In Informatica CDI, the customer manages the compute; in Informatica CDI-E, Informatica manages it. And in both offerings, the customer incurs the infrastructure cost.
Both Informatica CDI and Informatica CDI-E are available as an advanced serverless deployment option as shown in Figure 1. Advanced serverless is not another IDMC service; it is a deployment option. So, if an organization uses Informatica CDI or Informatica CDI-E but is incurring huge monthly bills due to high data workloads, the advanced serverless deployment option is the right choice. Why is this? Because the organization doesn’t have to manage the infrastructure, maintenance overhead and cost of processing high compute. Instead, Informatica takes on that responsibility.
To be clear, serverless does not mean that servers are not involved. It simply means that you don’t have to administer the servers or services in the architecture. Instead, you can spend your time on more high-value tasks, like business logic and running applications, rather than worry about scalability or server provisioning and maintenance.
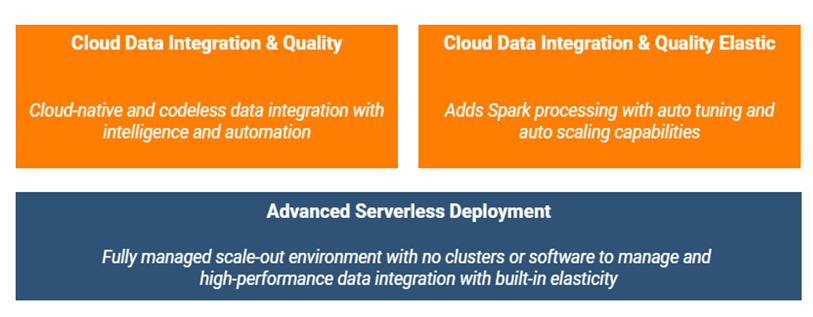
Figure 1. Flexible cloud data processing with Informatica Advanced Serverless.
Most importantly, Informatica CDI-E removes the cost overhead associated with intelligent cluster monitoring, elasticity and auto tuning, which are all driven by CLAIRE, our AI-powered metadata intelligence engine.
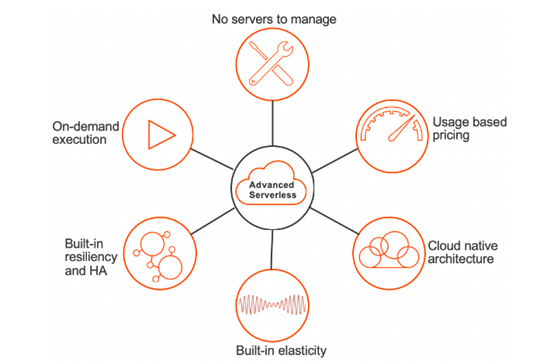
Figure 2: Key characteristics of Informatica Cloud Data Integration Advanced Serverless.
Because it gathers data from various data sources, Informatica CDI Advanced Serverless supports a wide range of cloud connectors and intelligent transformations. By using effective strategies and transformations, you can preview and direct data to targets that can be used for better business intelligence results and reporting. This can help create a competitive upper hand in today’s volatile economy.
Now let’s see how you can efficiently build and scale data pipelines using batch and streaming data with Apache Kafka and an advanced serverless deployment option for Informatica CDI and Informatica CDI-E.
How Apache Kafka and Informatica Cloud Data Integration Advanced Serverless Work Together
Because it manages and processes events in real time and supports different authorization and authentication mechanisms, Apache Kafka has become an instrumental open source ingestion backbone across various industries. In fact, the distributed event store and stream processing platform is being used by over 80% of the Fortune 100 companies in their tech stacks.1 Its power is indisputable: its durable, fault-tolerant, high-throughput distributed publish-subscribe mechanism helps organizations that rely on event streaming and batch processing architecture to modernize their data strategies and management.
In the ever-evolving world of data, the call for innovations and infrastructure overhead adds a roadblock for organizations dealing with extracting events from multiple sources. Not to mention, this also makes it challenging in terms of cost and workforce.
The advanced serverless deployment option for Informatica CDI enables data engineers to integrate real-time data ingested using Kafka at scale with zero infrastructure management. This improves their productivity since they will only be focused on building pipelines with real-time data versus the additional infrastructure cost.
With the support for the Informatica Kafka connector with Informatica CDI services, you can leverage the capabilities of Informatica CDI Advanced Serverless to resolve maintenance and cost overhead while intelligently scaling clusters on demand. This will help improve your operations, increase productivity, reduce cost overhead, decrease latency and jumpstart projects in minutes — all necessities in a crowded market.
Let’s review the key capabilities of using Apache Kafka and advanced serverless deployment for Informatica CDI and Informatica CDI-E.
Apache Kafka With Informatica Cloud Data Integration-Elastic Advanced Serverless
As a data engineer, you’re probably wondering how to use Informatica CDI-E with Apache Kafka. Below are some of the common questions we receive from customers using the Informatica Kafka connector with advanced serverless deployment for Informatica CDI and Informatica CDI-E:
- How do I set up and deploy the Apache Kafka cluster with Informatica CDI Advanced Serverless?
Assuming the Informatica CDI Advanced Serverless runtime environment is up and running, you can deploy a Kafka cluster with different authentication and authorization in your account using Amazon EC2 instances. You can also opt for the fully managed Apache Kafka cluster services (Amazon MSK) to avoid the operational overhead and complexity in managing various instances which — if managed improperly — can cost you exorbitant amounts. - How do the Informatica CDI and Informatica CDI-E services handle data in a serverless environment? The advanced serverless deployment option for Informatica CDI and Informatica CDI-E does not process any data outside the customer network. This eliminates any concerns with transferring data out through private links, which many other product offerings do.
- Does the Informatica CDI-E service deployed in a serverless environment support real-time data stream processing?
Yes, along with batch processing support, you can enable the state management capability support in Informatica CDI-E. This can help you achieve near streaming capability by consuming only the latest records from Apache Kafka topics upon successive schedulable runs, while retaining the states.
Achieve Your Data Integration Goals With Informatica Advanced Serverless Capability
Informatica CDI-E and Informatica CDI Advanced Serverless deployments address some of the major challenges associated with designing and running data pipelines. Let’s review a few.
- Complexity: With its easy-to-use, no-code GUI, Informatica CDI-E simplifies the designing of any workflows that can be integrated with an elastic runtime to handle and write data in virtually any format. The best part? You don’t need any programming knowledge to design the workflows: The GUI gives a remarkably simple interface for you to infix any upstream or downstream transformations with an Apache Kafka source to any of the Informatica-supported target connectors.
- Performance and cost: Optimizing Informatica CDI Advanced Serverless leverages Apache Spark through its robust parallel processing engine. This ensures data is delivered to the respective downstream targets effectively. Informatica CDI-E, in conjunction with Informatica CDI Advanced Serverless infrastructure management, optimizes performance and reduces costs. With Informatica CDI Advanced Serverless, you can control the allocated compute units per task while bringing up the runtime environments. This allows you to have control of the instances spawned and metered accordingly.
- Scalability: Informatica CDI-E Advanced Serverless provides a zero-worker node auto scalable K8s cluster on the serverless agent. This allows worker instances to scale up only when workloads are run and scale down to zero worker nodes if idle or no workloads are in the queue. Cluster auto scaler and auto tuner leverage CLAIRE to scale the clusters up and down the clusters and rebalance the workloads to maximize savings.
Bottom line? By harnessing the power of Apache Kafka for batch and event stream processing, combined with the advanced serverless capabilities of Informatica CDI and Informatica CDI-E, you can drive essential data engineering and data science initiatives at scale that will provide you with a distinct competitive advantage.
Next Steps
Are you ready to experience optimal event stream processing and AI-powered serverless data integration?
- Discover how the Informatica Kafka connector can ingest and process streaming and IoT sources to help drive mission critical data engineering projects.
- Get started now with a free, 30-day trial of Informatica Cloud Data Integration.


